
Comedy and Machine Learning: Visualizing Laughter with AI
Gettin nerdy and wordy and all up in your spectrograms

Can AI understand humor? Can it write jokes that aren’t dad jokes?

Maybe, but not without help. I spent months trying to create a step-by-step process for joke creation with ChatGPT, and it created some good ideas, but a lot of misses, and almost nothing stage-ready.
So how can we teach an AI system to better understand what’s funny and then possibly generate more, or help comedians edit and extend bits and chunks?
Can AI Even Recognize Laughter?
My first goal (which turns out to be a very hard problem in machine learning) is to get a model to recognize laughter in standup comedy wav files. There are other cool outcomes later, but this comes first- or AI will never really know what’s funny.
There are a number of train a machine learning model to recognize laughter, but the best way is to find examples, label them, and feed them into training a model.
I found (and cut with Audacity) about 240 samples (each) of laughter and non-laughter from well known comedians. It was super time consuming, but also interesting.
Jerry Seinfeld always waits for the laughter to start dying before talking again. Old school. Mazimizing laughs per minute.
Shane Gillis always steps on the laughs (he starts talking again before the laughter dies much at all).
Some comedians get applause for saying things the audience agrees with. Some don’t do that- they just want laughs.
Sometimes there’s “clappter” (however you spell it), which is a mixture of laughing and clapping. Dave Chappelle gets a lot of this (but of course he gets plenty of pure laughs, too)
I actually found six classes I wanted the models to be able to recognize, but I started with examples of two, just laughter and non-laughter (everything else).
What Does Laughter Look Like?
I thought it might be good to see the differences in the audio “features” of laughter and non-laughter.
Here’s what they look like:
Make of this what you will…
Laughter features (first row): [[ -50.09693909 80.32343292 -22.99516678 6.0877738 -4.76118898 -14.04821491 -12.54086208 -16.22932053 -2.28709435 7.28816175 -6.44158697 -5.79407358 -5.13950491 23.00972858 13.90343443 16.0432836 15.89234634 16.40953968 17.8631713 14.2217444 0.48435166 0.51376325 0.54789662 0.57742119 0.49908364 0.53901458 0.46707121 0.43442595 0.46188045 0.44469893 0.43231001 0.42846617]
Non-laughter features (first row): [[-1.82370071e+02 7.80228729e+01 -5.25930901e+01 -6.19965649e+00 -2.23852386e+01 -2.19353790e+01 -1.70868073e+01 -1.42146263e+01 -8.10447788e+00 -2.13113928e+00 -1.08685989e+01 8.35287035e-01 -1.28426485e+01 1.63226549e+01 1.86515970e+01 1.95840327e+01 1.85919757e+01 1.94330833e+01 2.08034012e+01 5.37840254e+01 2.28045031e-01 2.91352153e-01 3.85297477e-01 3.56220812e-01 2.82024801e-01 3.55979413e-01 4.11764979e-01 4.17518109e-01 3.40910167e-01 3.31881285e-01 2.81164318e-01 2.31433854e-01]
Here’s what ChatGPT thought about that:
Laughter might be characterized by more consistent and less extreme MFCC values, reflecting the tonal qualities of human laughter, which tends to be less variable in its spectral features.
Non-Laughter sounds could include a wider variety of noises (like silence, clapping, etc.), which might lead to more variation in these features.
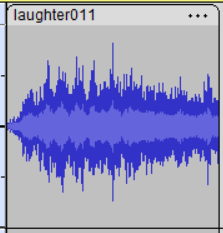
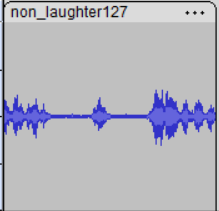
I can tell you just from cutting pieces of laughter and speech from the WAVs, that’s definitely true. You see a pretty common pattern in a group laugh, while both speech and clapping are much more stacatto.
Laughter in Audacity:
Comedian talking:
Some more visualizations

You like MFCC’s? You like histograms? Well you’re gonna love this!
Here’s an animated gif of the histograms for the 31 MFCC features:
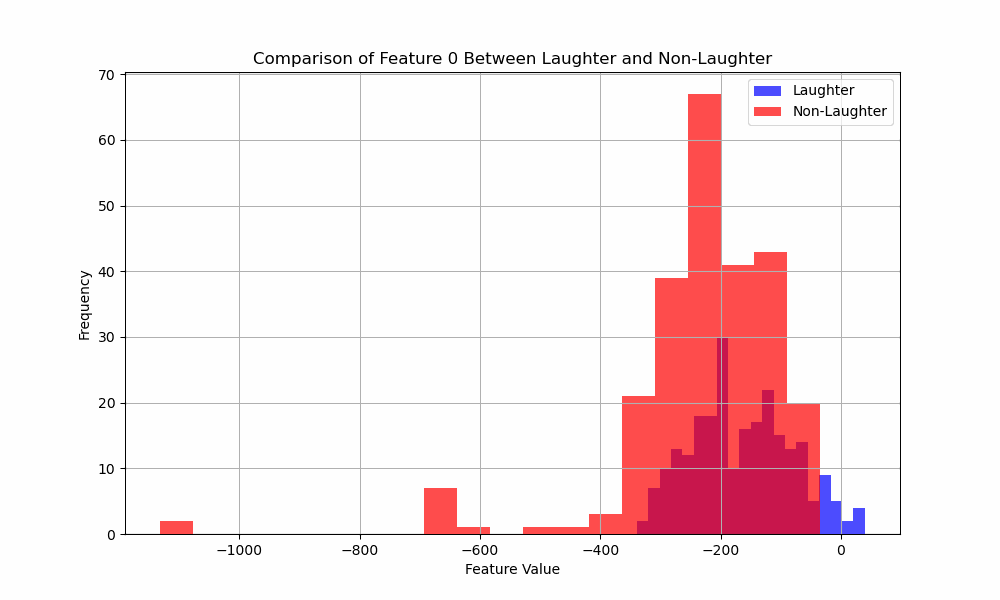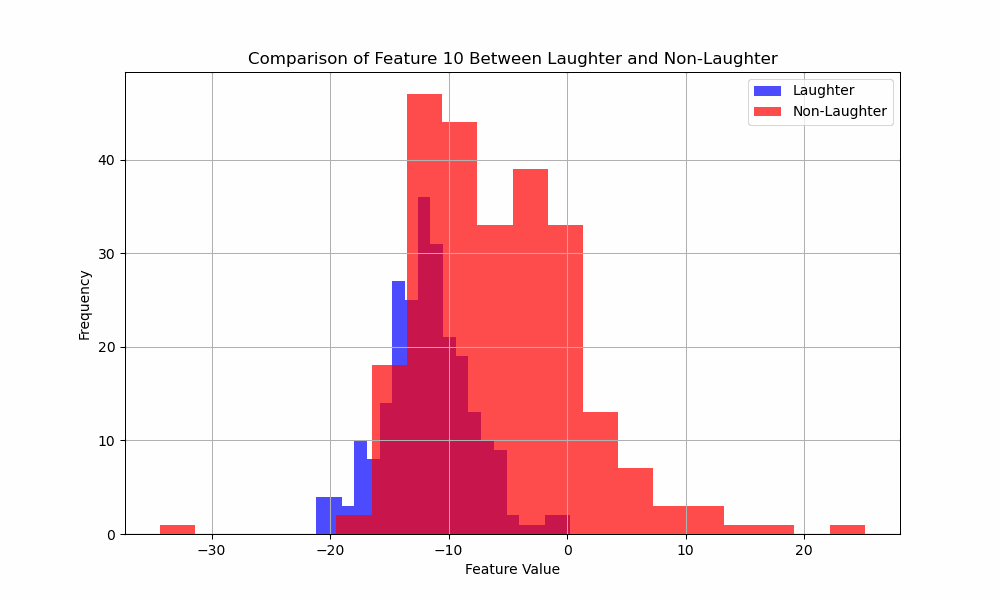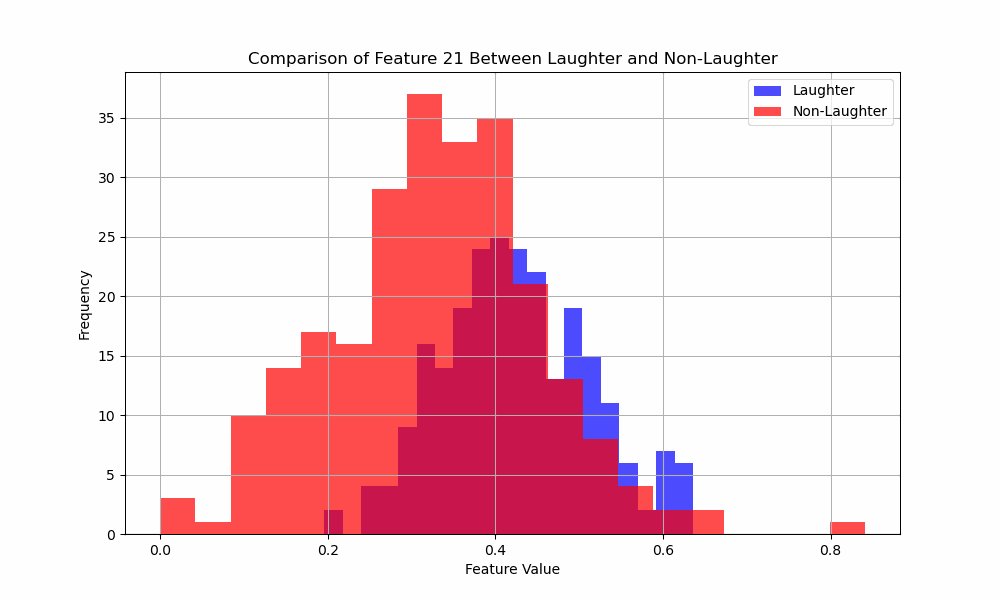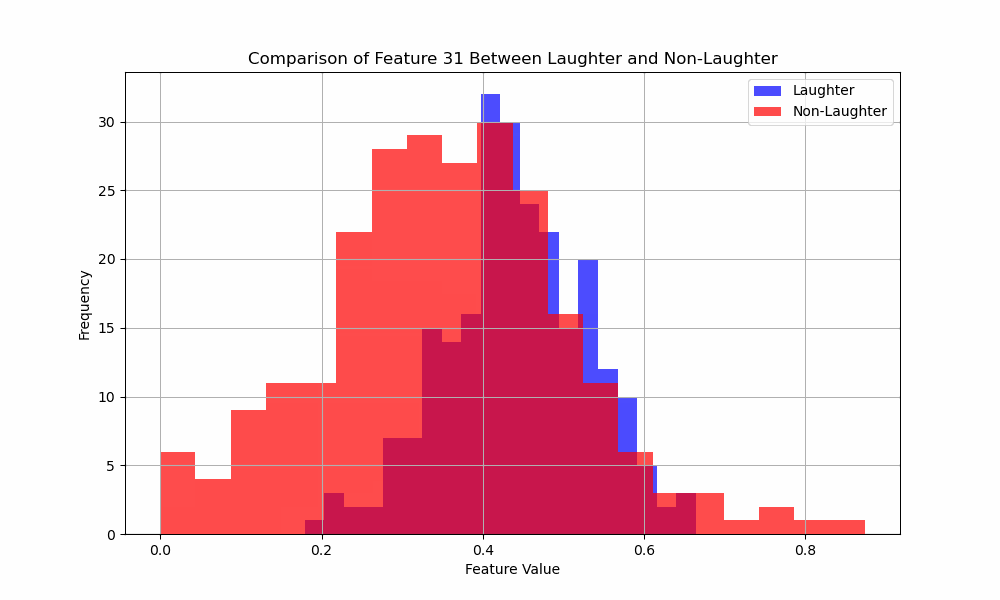
Exciting. But what does it all mean?
It means I have more work to do.
I created a model from this that says it can recognize the laughter with ~93% accuracy, but in my first test, it’s really inaccurate. That means it probably is overfitted, but we’ll see.
This is going to be a multipart series… stay tuned!